· tutorials · 8 min read
skeptrune (Nick K)
Building Search For the YC Company Directory With Trieve, Bun, and SolidJS
Trieve tutorial covering how to use Trieve in order to build an updated search UX for the YC company directory using Bun and SolidJS.

Introduction
Want to sign on Trieve as a Vendor or just talk to a human? Book a meeting with a founder at Trieve here on cal.com. Also star us on Github here if you have not already!
This blog post is going to act as a tutorial showing you how to use Trieve in order to build updated search for the YC company directory using bun and SolidJS.
See the complete code for this tutorial at github.com/devflowinc/yc-companies and try the finished project at yc.trieve.ai.
Step 1. Exploratory Data Analysis
Before doing anything else, we need to figure out how we are going to scrape the data in order to build this demo. The first step of that is looking at the public YC company directory and seeing what public data is available.
1. Each listed company is represented via its own page linked in the search result list
Turns out that there is a lot you can learn from inspect element. In this case by looking at the DOM and having the context that a lot of YC software development is in Rails, I am willing to gamble that there is a “view” for each company. This is because Rails traditionally follows a MVC (Model View Controller) pattern.
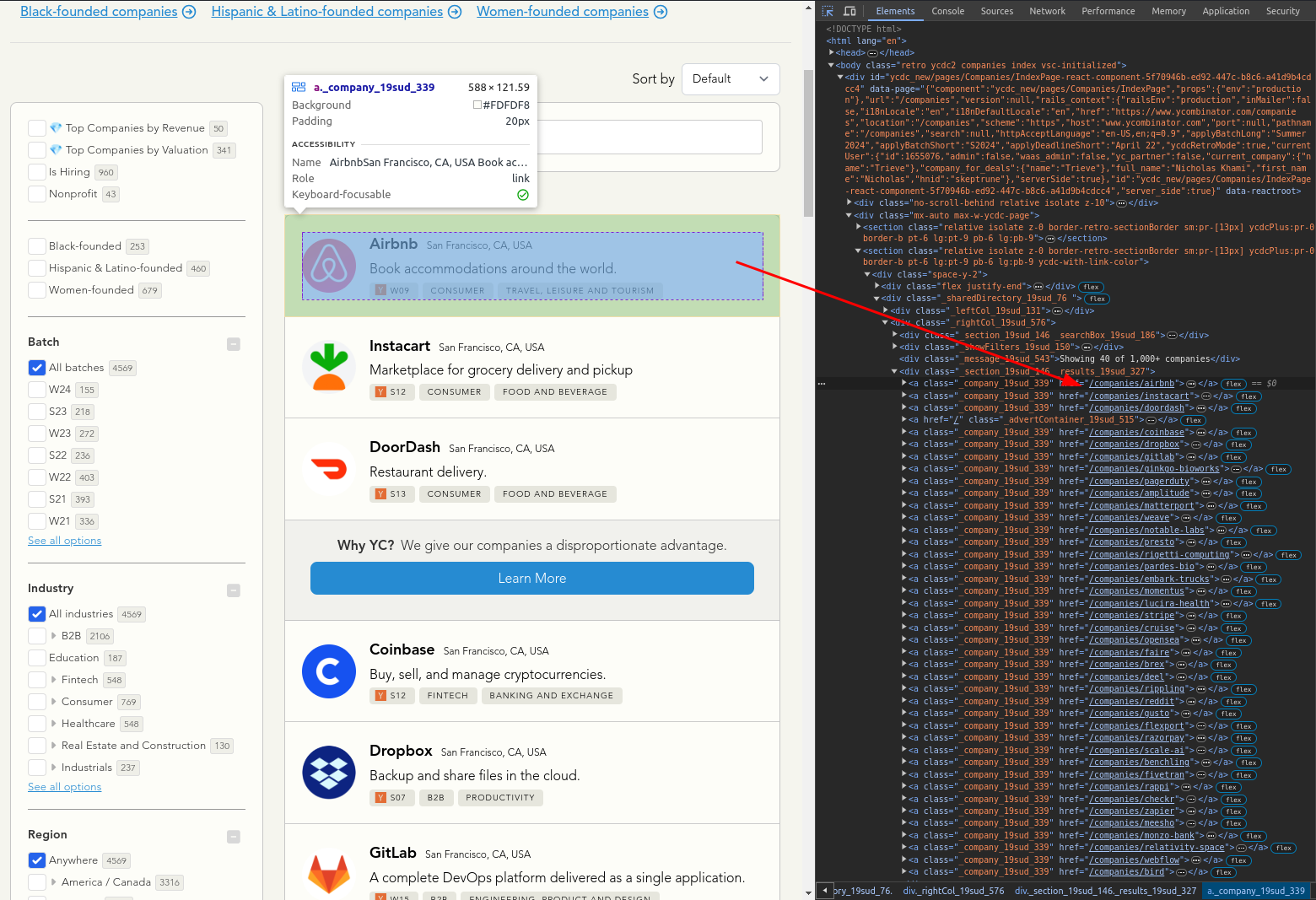
2. The company view offers the data in a neat JSON object as an HTML attribute!
Aha! I feel a sense of vindication looking at the DOM for AirBNB as it does seem to be a traditional view. Even luckier, all of the data about a given company is present in an attribute with in the first element of the page.
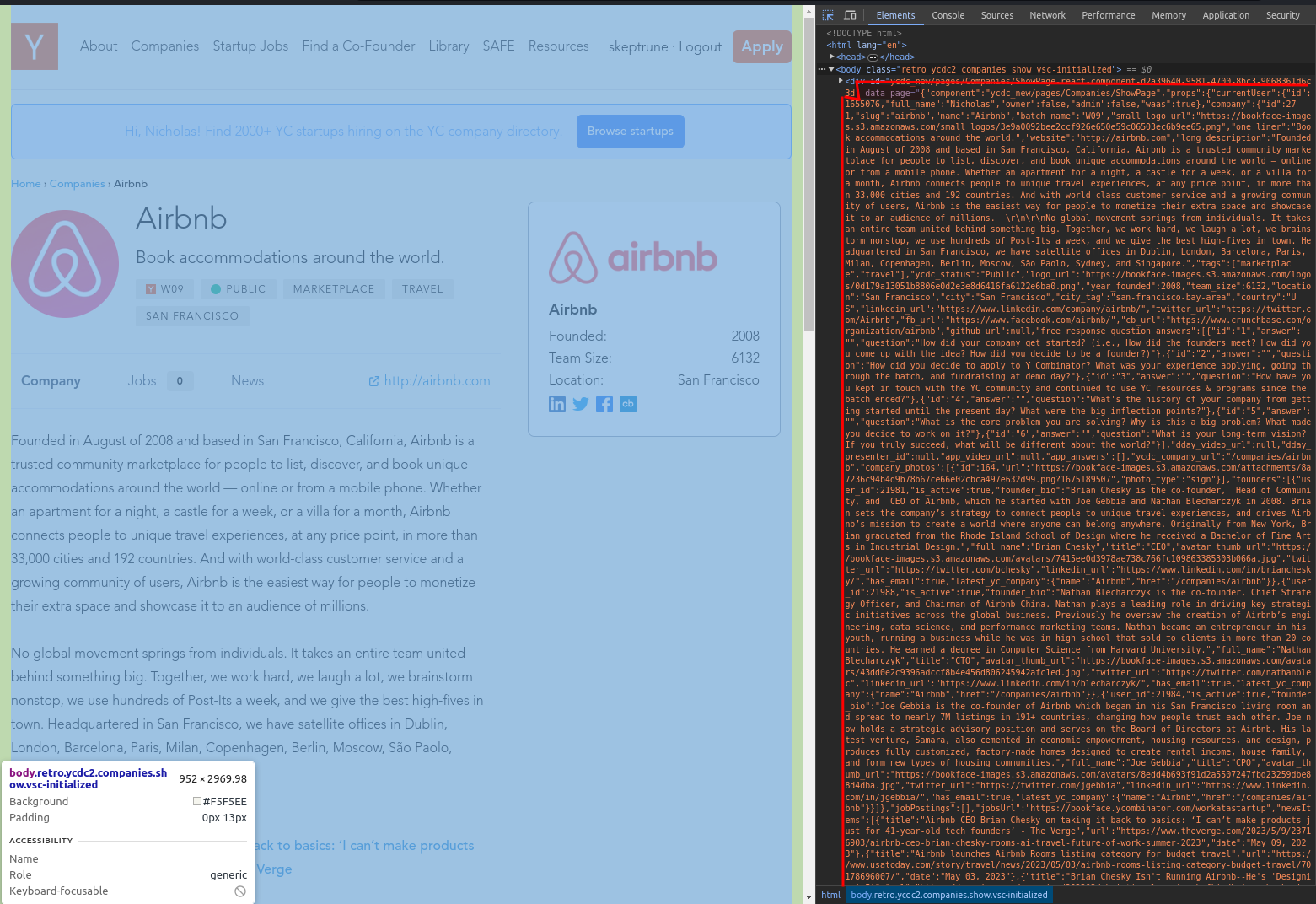
3. Plan out an approach for pulling this JSON object from the DOM for every company
We have discovered that each YC company in the directory has a page with a JSON object containing all of its data, now what?
1. Write a script to get the link to every company available in the directory
I don’t think it’s too relevant to this tutorial to explain how I did this, but here is a a link to the full github gist containing the script I pasted into the console to get all of the company links if you are interested in reading it. My co-founder Denzell always gets a laugh over how much work I’m willing to do in the console.
4. Settle on a language for pulling each company’s view from the link and getting the JSON object
Typically in these spots I pick python because beautifulsoup4 is such an amazing package for these kinds of things done headlessly on a server. However, I am more comfortable in JS and vaguely knew that bun, a new javascript server runtime written in Zig, was advertised as a good solution as well.
Because I wanted to try Bun out and this should be a relatively small task either way, I opted for typescript ran via bun.
Step 2. Sign up For Trieve’s Free Cloud To Get an API_KEY and DATASET_ID
- Navigate to dashboard.trieve.ai and sign in or make an account
- On the first page you see, click create dataset
- On the dataset creation page, save your
dataset_idto use later - Click the button to create an API key
- Create a Read+Write type API key, save the value to use later on
Step 3. Use bun to pull the DOM containing the view for each company and extract the data from it
1. Install bun and scaffold an empty project using bun init
I am going to cede to the bun docs for bun init here instead of detailing how this works. On the bun docs page, you can also find an install guide.
2. Use the happy-dom package to headlessly pull data from the View for each company
To start, run bun add -d @happy-dom/global-registrator to add happy-dom as a dependency to your bun project.
Now, at the top of your index.ts file we are going to import Window from happy-dom and instantiate a document to use querySelector with later on.
Note that we add the docstring comment for the dom lib such that we get the benefit of typescript types for the DOM objects.
/// <reference lib="dom" />
import { Window } from "happy-dom";
const window = new Window();
const document = window.document;
Continuing, we are going to write a function to make a GET request for the HTML page at each company’s URL and extract its data.
const processLink = async (companyUrl: string, groupIds: string[]) => {
try {
const pageRespHtml = await fetch(companyUrl);
const pageRespText = await pageRespHtml.text();
document.body.innerHTML = pageRespText;
// get the first div that has a data-page attribute
const divs = document.body.querySelectorAll("div");
divs.forEach(async (div) => {
const dataPage = div?.getAttribute("data-page");
if (!dataPage) {
return;
}
const bulkData = JSON.parse(dataPage).props;
const companyData = bulkData.company;
await processCompanyChunk(companyData, groupIds);
});
} catch (e) {
console.error("error processing link", companyUrl, e);
return;
}
};
3. Stitch each companies structured data into an unstructured text blob and send it to Trieve for indexing and storage
First, because Trieve does not yet have a typescript SDK, we will specify the request data for creating a chunk as an interface.
export interface CreateChunkData {
chunk_html: string;
group_ids: string[];
link: string;
tag_set: string[];
tracking_id: string;
metadata: Object;
}
Next, we will write a function that accepts a CreateChunkData type object and then uses it to call Trieve’s create_chunk route.
const createChunk = async (chunkData: CreateChunkData) => {
const response = await fetch(`${API_URL}/chunk`, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: Bun.env.API_KEY ?? "",
"TR-Dataset": Bun.env.DATASET_ID ?? "",
},
body: JSON.stringify(chunkData),
});
if (!response.ok) {
console.error("error creating chunk", response.status, response.statusText);
const respText = await response.text();
console.error("error creating chunk", respText);
return "";
}
const responseJson = await response.json();
if (!response.ok) {
console.error("error creating chunk", responseJson.message);
return "";
}
console.log("success creating chunk", responseJson.chunk_metadata.id);
const chunkId = responseJson.chunk_metadata.id;
return chunkId as string;
};
To fully process the data we still need to stitch each company’s structured data into an unstructured blob which we can use for the chunk_html.
const processCompanyChunk = async (
bulkDataCompany: any,
groupIds: string[],
) => {
const group_id = await createChunkGroup(
bulkDataCompany.name as string,
bulkDataCompany.one_liner as string,
);
const companyName = "<h1>" + bulkDataCompany.name + "</h1>";
const companyOneLiner = "<h3>" + bulkDataCompany.one_liner + "</h3>";
const companyLongDescription =
"<p>" + bulkDataCompany.long_description + "</p>";
const companyLocation =
"<p>" +
"Located in " +
bulkDataCompany.location +
", " +
bulkDataCompany.country +
" and founded in " +
bulkDataCompany.year_founded +
"</p>";
const chunk_html =
"<div>" +
companyName +
companyOneLiner +
companyLongDescription +
companyLocation +
"</div>";
const link = bulkDataCompany.ycdc_company_url;
const tag_set =
bulkDataCompany.batch_name +
"," +
bulkDataCompany.tags.join(",") +
"," +
bulkDataCompany.city_tag;
const tracking_id = bulkDataCompany.id.toString();
const company_name = bulkDataCompany.name;
const company_one_liner = bulkDataCompany.one_liner;
const company_long_description = bulkDataCompany.long_description;
const batch = bulkDataCompany.batch_name;
const company_location = bulkDataCompany.location;
const company_city = bulkDataCompany.city;
const company_city_tag = bulkDataCompany.city_tag;
const company_country = bulkDataCompany.country;
const company_year_founded = bulkDataCompany.year_founded;
const company_website = bulkDataCompany.website;
const company_linkedin = bulkDataCompany.linkedin_url;
const company_twitter = bulkDataCompany.twitter_url;
const company_facebook = bulkDataCompany.facebook_url;
const company_crunchbase = bulkDataCompany.cb_url;
const company_logo_url = bulkDataCompany.small_logo_url;
const metadata = {
company_name,
company_one_liner,
company_long_description,
batch,
company_location,
company_city,
company_city_tag,
company_country,
company_year_founded,
company_website,
company_linkedin,
company_twitter,
company_facebook,
company_crunchbase,
company_logo_url,
};
const chunkData: CreateChunkData = {
chunk_html,
group_ids: [group_id, ...groupIds],
link,
tag_set: tag_set.split(","),
tracking_id,
metadata,
};
await createChunk(chunkData);
return group_id;
};
Notice that above, we keep all of the chunk’s native data as metadata on the chunk resource we are creating. We do this to make our life easier when building the final frontend which users are going to interact with.
See the details of running these functions for each company’s URL in the full implementation on Github at github.com/devflowinc/yc-companies/bun-scraper.
Step 4. Build a SolidJS SPA for interacting with the dataset via search
The entire frontend application for this tutorial is available at yc.trieve.ai and written in a single typescript file which you can view at github.com/devflowinc/yc-companies/blob/main/src/App.tsx.
I strongly recommend reading the SolidJS documentation to get a more in-depth understanding of how to use SolidJS in your own projects. In my opinion, it is beyond the scope of this tutorial to go into depth about how we used SolidJS to fully build out the frontend. However, if you are interested. let me know and I may write a part 2!
In this post, I primarily want to focus on how we search the dataset we indexed and stored in the previous step using Trieve.
type SearchType = "semantic" | "hybrid" | "fulltext";
const searchCompanies = async (
curSortBy: string,
curPage: number,
curBatchTag: string,
) => {
setFetching(true);
const response = await fetch(`${apiUrl}/chunk/search`, {
method: "POST",
headers: {
"Content-Type": "application/json",
"TR-Dataset": datasetId,
Authorization: apiKey,
},
body: JSON.stringify({
page: curPage,
query: searchQuery(),
search_type: searchType(),
tag_set:
curBatchTag === "all batches" ? [] : [curBatchTag.toUpperCase()],
highlight_results: false,
get_collisions: false,
}),
});
const data = await response.json();
const scoreChunks = data.score_chunks;
if (curSortBy === "recency") {
scoreChunks.sort(
(a: any, b: any) =>
parseInt(b.metadata[0].metadata.batch.slice(-2)) -
parseInt(a.metadata[0].metadata.batch.slice(-2)),
);
}
if (curPage > 1) {
setResultChunks((prevChunks) => prevChunks.concat(scoreChunks));
} else {
setResultChunks(scoreChunks);
}
setFetching(false);
};
There are 3 available search modes: semantic, hybrid, and fulltext. Semantic search uses dense vector embeddings created with a Jina model and fulltext uses sparse vectors created via SPLADEv2. Hybrid is a mix of both where the final result set is ordered with bge-reranker.
Conclusion
Build with Trieve! Join us on Matrix or Discord and tell us about what you want to build. Our community would love to hear about your ideas and plans to help you build however we can.
Finally, if you liked this tutorial, please star us at github.com/devflowinc/trieve!
Cheers! Hopefully I get to hear from you soon. Feel free to book a meeting with me here on cal.com, follow on X, or connect on LinkedIn.